딥러닝(1) - 퍼셉트론
1. 들어가기 전에
1.1. AI의 역사
- 1943년: 최초 신경망 모델 제안
- 1950년: 앨런 튜링이 튜링 테스트 제안
- (첫 번째 AI 붐) 1950년대 후반 ~ 1970년대 전반
- 1956년 : 미국 다트머스의 학회에서 AI 이란 용어 처음 사용
- 1957년 : 코넬 항공 연구소 프랑크 로젠이 Perceptron 고안
- (두 번째 AI 붐) 1980년대: 주로 컴퓨터가 자율적으로 배우고 결정하는 종류가 아닌 인간으로부터 지식을 얻음
- 1990년대: 세계 체스 챔피언을 물리 친 AI
- (세 번째 AI 붐) 2010년대: 딥 러닝 (머신 러닝)이라는 새로운 기술이 각광

1.2. AI, ML, DL
- AI(Artificial Intelligence): 사고나 학습 등 인간이 가진 지적 능력을 컴퓨터를 통해 구현하는 기술
- ML(Machine Learning): 컴퓨터가 스스로 학습하여 인공지능의 성능을 향상시키는 기술
- DL(Deep Learning): 인간의 뉴런과 비슷한 인공신경망 방식으로 정보를 처리하는 기술

1.3. Machine Learning
- 먼저 그림과 같이 컴퓨터에게 문제와 답을 알려줍니다.
- 이후, 관련 문제를 내면 컴퓨터가 정답을 알아 맞추게 됩니다.
이것이 가능한 이유는 컴퓨터가 데이터(문제) 답(label)으로 학습하며 직접 프로그램(알고리즘)을 작성하기 때문

종류
1) 지도학습 (Supervised Learning)
훈련데이터와 정답을 가지며, 데이터를 분류/예측하는 함수를 만들어내는 기계학습 방법
- 분류: KNN(K-Nearest Neighbors), 나이브 베이즈, 결정트리, 서포트 벡터머신, 아프리오 알고리즘
- 회귀: 선형회귀(Linear Regression), 신경망
2) 비지도학습 (Unsupervised/Predictive Learning)
정답없이 훈련데이터만 가지고 데이터로부터 숨겨진 패턴을 탐색하는 기계학습의 방법
- 클러스터링: 연관규칙(apriori), k-means
3) 강화학습 (Reinforcement Learning)
어떤 환경에서 정의된 에이전트가 현재 상태를 인식하여 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하는 방법
1.4. Deep Learning
- 딥 러닝은 최신 인공 신경망(Artificial neural network) 기술로 인간 두뇌의 메커니즘을 시뮬레이션
- 인간의 뇌는 정보를 전달하기 위해 뉴런(neuron)과 뉴런들을 연결하는 시냅스(synapse)로 구성
- 인공 신경망(또는 단순히 신경망이라고 함)은 이러한 뉴런과 시냅스를 모델링
- 이 모델은 두 번째 AI 붐 중에 적극적으로 연구되었지만 레이어 매우 작았고, 이후 기술 발전으로 인해 대규모 네트워크로 확장되어 컴퓨터가 심층 학습을 실행할 수 있게됨

2. Perceptron
2.1. 개념
- 1943년 미국 신경외과 의사인 워렌 멕컬록에 의해서 발단이 되었고, 1957년 코넬 항공 연구소(Cornell Aeronautical Lab)의 프랑크 로젠블라트(Frank Rosenblatt)가 퍼셉트론 알고리즘을 고안했습니다.
Neuron과 Threshold
- 뉴런은 특정 자극(impulse) 이 있다면 그 자극이 어느 역치(threshold) 이상이여야 활성화(activation)
- 활동전위(action potential)가 축삭(axon)을 따라 내려가면서 세포막 안팎의 극성이 변화 -> 다른 뉴런에서 온 신호에 반응하여 막이 역치(threshold) 전위에 도달하면 Na+ 및 K+ 개폐 이온 채널이 여닫힘 -> 활동전위가 시작될 때 Na+ 채널이 열리고 Na+가 축삭 안으로 들어와 탈분극(Depolarization) -> 재분극은 K+ 채널이 열리고 K+가 축삭 밖으로 나갈 때 일어남 -> 채널의 개폐로 세포 안팎 극성이 변화 -> 신경 자극은 한 방향으로만 이동하여 축삭 말단(axon ending)에서 다른 뉴런으로 신호를 전달


Perceptron과 $\theta$
- 뉴런을 모방함

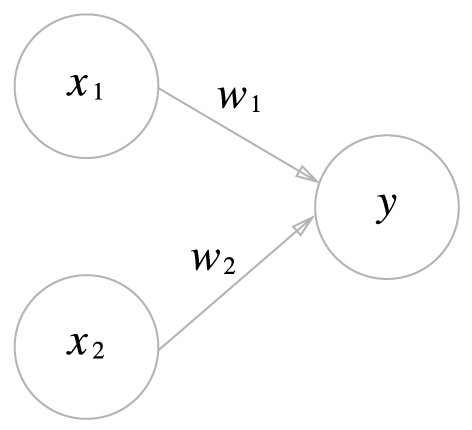
- 입력(input) 신호의 총합이 정해진 임계값($\theta$) 넘었을 때 $1$을 출력(output), 넘지 못하면 $0$ 또는 $-1$ 출력
- 각 입력신호에 고유한 weight 부여되며 기계학습은 이 weight(입력을 조절하니 매개변수로도 볼 수 있음)의 값을 정하는 작업




2.2. 학습 방법
- 처음에는 인간이 임의로 weight로 시작
- 머신이 학습 데이터를 퍼셉트론 모형에 입력하며 분류가 잘못됐을 때 weight를 개선 (인간이 문제 틀렸을 때 다시 푸는 것과 유사 -> 학습이라고 부름)

2.3. 가중치(weight)와 편향(bias)
- 앞의 퍼셉트론 수식에서 나오는 세타$\theta$를 $-b$로 치환하여 좌변으로 넘기면 아래와 같이 되며 여기에서 $b$를 편향(bias)라고 할 수 있다.
- 기계학습 분야에서는 모델이 학습 데이터에 과적합(overfitting)되는 것을 방지하는 것이 중요
- 과적합: 모델이 엄청 유연해서 학습 데이터는 귀신같이 잘 분류하지만, 다른 평가 데이터를 넣어봤을 때는 제대로 성능을 발휘하지 못하는 것을 말한다. 어느 데이터를 넣어도 일반적으로 잘 들어맞는 모델을 만드는 것이 중요하다.
- 편향이 높을 수록 그만큼 분류의 기준이 엄격하다는 것을 의미하며 모델이 간단해지는 경향이 있고 (변수가 적고 더 일반화 되는 경우) 오히려 과소적합(underfitting)의 위험이 발생하게 된다.
- 편향이 낮을수록 한계점이 낮아 데이터의 허용범위가 넓어지는 만큼 학습 데이터에만 잘 들어맞는 모델이 만들어질 수 있으며 모델이 더욱 복잡해질 것이다. 허용범위가 넓어지는 만큼 필요 없는 노이즈가 포함될 가능성도 높다. 이를 편향과 분산의 트레이드오프 관계라고 보통 부른다.
2.4. 선형 분류(linear classifier)
- 퍼셉트론의 출력 값은 앞에서 말했듯이 1 또는 0(or -1)이기 때문에 학습 데이터가 선형적으로 분리될 수 있을 때 적합한 알고리즘
- 선형 분류는 평면 상에 선을 쫙 그어서 여기 넘으면 A, 못 넘으면 B 이런식으로 선을 기준으로 분류하는 것 의미
- 학습이 반복될수록 선 기울기 달라짐 (학습을 하면서 weight가 계속 조정됨)

2.5. 퍼셉트론의 한계점
- AND와 OR과 같은 선형 데이터는 분류 가능하지만, XOR과 같은 형태의 비선형 데이터는 분류가 불가능하다
-
AND 게이트: x1과 x2 중 모두(and) 1일때 1을 출력
$x_1$ $x_2$ $y$ 0 0 0 0 1 0 1 0 0 1 1 1 python numpy 패키지
- 숫자배열 연산을 위한 라이브러리입니다.
- numpy array는 파이썬 리스트보다 속도가 빠르며 리스트간 연산에 편의성을 제공합니다.
- sorting이나 indexing, intersection을 찾는 경우에도 속도가 빠릅니다.
- 평균, 중앙값, 최빈값, 사분위수, 분산, 표준편차를 찾는 경우에도 리스트보다 훨씬 코드가 간단하고 속도가 빠릅니다.
import numpy as np def AND(x1, x2): x = np.array([x1,x2]) w = np.array([0.5,0.5]) theta = 0.7 # print(x1, x2) # print(w*x) if np.sum(w*x) <= theta: # array의 곱셈의 합 return 0 else: return 1 inputData = np.array([[0,0],[1,0],[0,1],[1,1]]) for x in inputData: print(x[0],", ",x[1]," ==> ",AND(x[0],x[1]), sep = '') -
OR 게이트: x1과 x2 중 하나만(or) 1이면 1을 출력
$x_1$ $x_2$ $y$ 0 0 0 0 1 1 1 0 1 1 1 1 def OR(x1,x2): x = np.array([x1,x2]) w = np.array([0.5,0.5]) theta = 0 if np.sum(w*x) <= theta: return 0 else: return 1 inputData = np.array([[0,0],[1,0],[0,1],[1,1]]) for x in inputData: print(x[0],", ",x[1]," ==> ",OR(x[0],x[1]), sep = '') -
NAND 게이트: x1과 x2 중 하나만(or) 0이면 1을 출력
$x_1$ $x_2$ $y$ 0 0 1 0 1 1 1 0 1 1 1 0 def NAND(x1,x2): x = np.array([x1,x2]) w = np.array([-0.5,-0.5]) theta = -0.7 if np.sum(w*x) <= theta: return 0 else: return 1 inputData = np.array([[0,0],[1,0],[0,1],[1,1]]) for x in inputData: print(x[0],", ",x[1]," ==> ",NAND(x[0],x[1]), sep = '') -
XOR 게이트: x1과 x2 중 어느 한쪽이 1일 때만 1을 출력 (둘다 1이면 0 출력)
$x_1$ $x_2$ $y$ 0 0 0 0 1 1 1 0 1 1 1 0 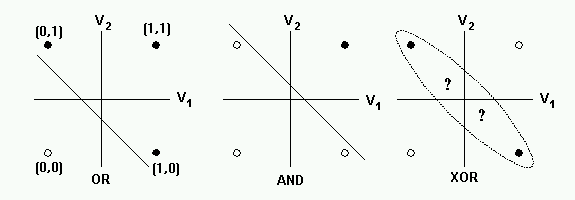
-
- 한계점이 밝혀지면서 한동안 소외 받았고, 퍼셉트론을 제시한 로젠블랫은 자살 같은 사고로 세상을 떠났고 시간이 흐른 뒤에야 그의 업적이 재조명 받았다.
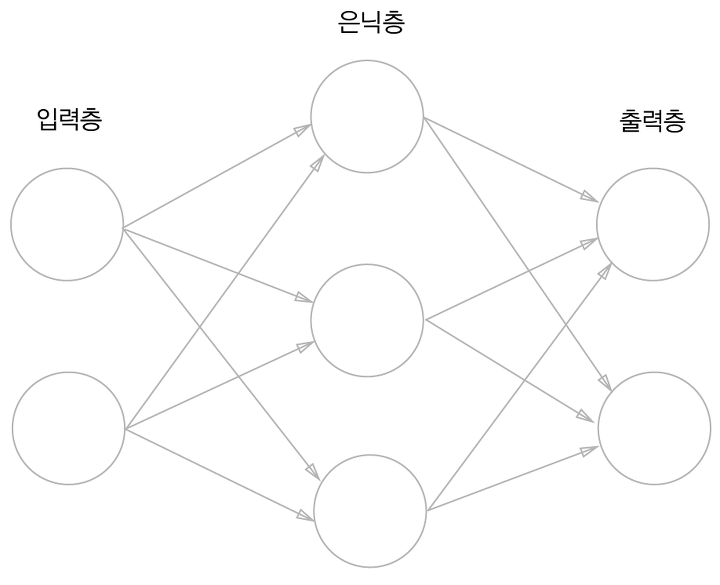
2.6. 다층 퍼셉트론(Multi Layer Perceptron)을 통한 한계 극복
- 단층 퍼셉트론: AND, OR, NAND 게이트와 같이 입력층에 가중치를 곱해 바로 출력되는 퍼셉트론
- 다층 퍼셉트론: 퍼셉트론을 층으로 쌓은 것으로,입력층과 출력층 사이 은닉층이 존재하는 것
- 위와 같은 다층 퍼셉트론(AND, OR, NAND를 조합)으로 XOR 게이트를 구현할 수 있음
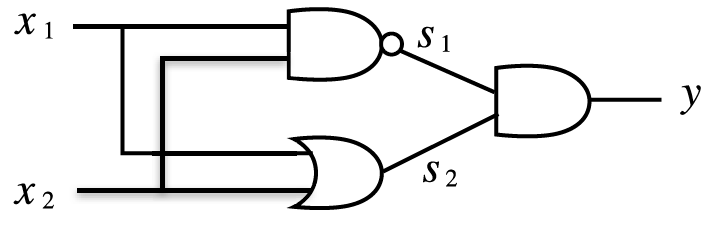

$x_1$ $x_2$ $s_1$ $s_2$ $y$ 0 0 1 0 0 0 1 1 1 1 1 0 1 1 1 1 1 0 1 0
def XOR(x1, x2):
return AND(NAND(x1,x2), OR(x1,x2))
inputData = np.array([[0,0],[1,0],[0,1],[1,1]])
for x in inputData:
print(x[0],", ",x[1]," ==> ",XOR(x[0],x[1]), sep = '')
댓글남기기